XML作为一种重要的文件格式,应用面非常之广。从ASP.NET的web.config,到Android的页面设计开发,Webservice通信等。有时候难免需要我们通过程序进行创建与解析,最近刚完成一个C++项目,就需要读取XML配置文件,关于XML解析器的选择很多,可以参考:http://www.metsky.com/archives/578.html。
个人比较喜欢Apache的开源项目,所以使用的是:Xerces。它的使用方法,其实官方上已经有很多demo,详见:http://xerces.apache.org/xerces-c/samples-3.html。个人觉得DOMCount比较实用,下面分享一下我的个人实践。通过DOM方式读取XML中指定节点的属性及文本值。
开发环境:Visual studio 2013
下载源码就不说了,地址:http://apache.dataguru.cn//xerces/c/3/sources/xerces-c-3.1.2.zip,无法下载,可以去http://xerces.apache.org/xerces-c/download.cgi下载。
首先,编译XercesLib工程,得到xerces-c_3_1D.dll,xerces-c_3D.lib两个文件,其次需要在目标工程添加这2个文件,以及相应的头文件,然后是一点配置,接下来就是编码。
下面详细分步进行:
1.VS 2013 打开xerces-c-3.1.2\projects\Win32\VC12\xerces-all\xerces-all.sln
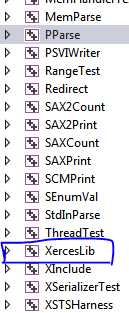
选中XercesLib->右击->编译
2.复制xerces-c-3.1.2\Build\Win32\VC12\Debug文件夹下的xerces-c_3_1D.dll,xerces-c_3D.lib文件到目标工程的编译输出目录下(有编译过一次才有),如:~\ Debug\ 下面。
3.复制xerces-c-3.1.2下的src文件夹到目标工程下。
4.配置include Directories 增加.\src,
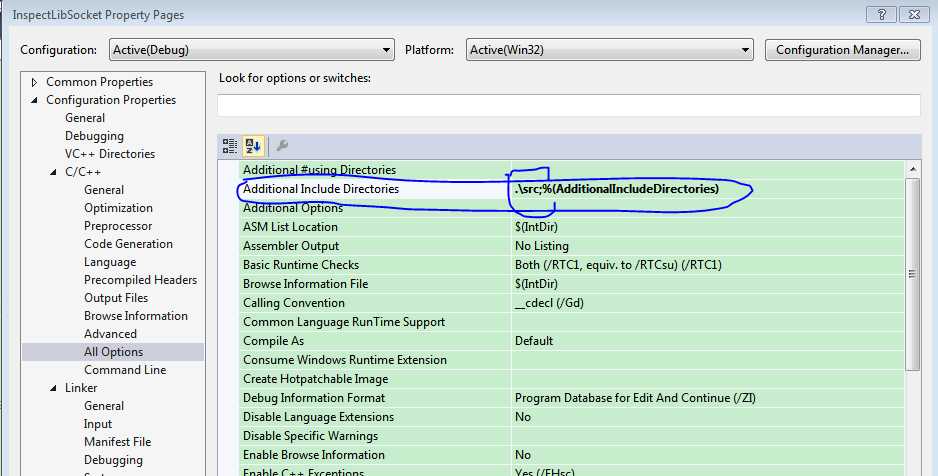
配置Dependencies 增加xerces-c_3D.lib,Library Directories 增加$(OutDir)(即编译输出目录)

2-4步是所有调用动态库的通用配置方法,如果明白其中的原理,其实可以灵活配置。
XML文件内容如下:
<?xml version="1.0" encoding="UTF-8"?> <config> <child> <node1> <list name="1">test11</list> <list name="2">test12</list> </node1> <node2> <list name="1">test21</list> <list name="2">test31</list> </node2> <node3> <list name="1">test31</list> <list name="2">test32</list> </node3> </child> </config>
5.开始实现编码。
5.1包含头文件
1 #include <xercesc/util/PlatformUtils.hpp> 2 #include <xercesc/dom/DOM.hpp> 3 #include <xercesc/sax/HandlerBase.hpp> 4 #include <xercesc/parsers/XercesDOMParser.hpp>
5.2初始化环境
1 try { 2 XMLPlatformUtils::Initialize(); 3 } 4 catch (const XMLException& toCatch) { 5 // Do your failure processing here 6 return; 7 } 8 /// 9 XercesDOMParser *parser = new XercesDOMParser(); 10 parser->setValidationScheme(XercesDOMParser::Val_Always); 11 parser->setDoNamespaces(true); // optional 12 13 ErrorHandler* errHandler = (ErrorHandler*) new HandlerBase(); 14 parser->setErrorHandler(errHandler);
5.3载入XML文件
1 try { 2 parser->parse(“D:\RUN.XML”); 3 } 4 catch (const XMLException& toCatch) { 5 char* message = XMLString::transcode(toCatch.getMessage()); 6 cout << "Exception message is: \n" 7 << message << "\n"; 8 XMLString::release(&message); 9 return; 10 } 11 catch (const DOMException& toCatch) { 12 char* message = XMLString::transcode(toCatch.msg); 13 cout << "Exception message is: \n" 14 << message << "\n"; 15 XMLString::release(&message); 16 return; 17 } 18 catch (...) { 19 cout << "Unexpected Exception \n"; 20 return; 21 }
5.4开始解析
1 DOMDocument *doc = parser->getDocument(); 2 DOMElement *root = doc->getDocumentElement();//读取根节点
5.5 找对应节点值与属性
1 DOMNode *DN=root; 2 DN = findchildNode(DN, "child");//查找child子节点 3 for (DN = DN->getFirstChild(); DN != 0;DN = DN->getNextSibling()) 4 {//遍历node1,2,3子节点 5 if (DN->getNodeType() == DOMNode::ELEMENT_NODE)//这个是必要的,因为如果不判断类型,实际上每一个节点会有一个TEXT_NODE,而且是第一个节点 6 { 7 if (XMLString::compareString(XMLString::transcode(findchildNode(DN, "list")->getAttributes()->getNamedItem(XMLString::transcode("name"))->getNodeValue()), XMLString::transcode("1")) == 0) 8 {//找到<list name=”1”>的节点 9 cout <<”对应节点值为:” << XMLString::transcode(findchildNode(DN, " list")->getTextContent())<<endl; 10 //DO IT CODE 11 … 12 13 }; 14 15 } 16 } 17 XMLPlatformUtils::Terminate();//释放环境
下面是findchildNode函数的代码
1 DOMNode* findchildNode(DOMNode *n, char *nodename) 2 {//寻找n节点下子节点名为nodename的节点 3 try 4 { 5 for (DOMNode *child = n->getFirstChild(); child != 0; child = child->getNextSibling()) 6 { 7 if (child->getNodeType() == DOMNode::ELEMENT_NODE && XMLString::compareString(child->getNodeName(), XMLString::transcode(nodename)) == 0) 8 { 9 return child; 10 } 11 } 12 } 13 catch (const XMLException& toCatch) 14 { 15 char* message = XMLString::transcode(toCatch.getMessage()); 16 cout << "Exception message is: \n" 17 << message << "\n"; 18 XMLString::release(&message); 19 } 20 return 0; 21 }
5.6 记得释放环境
XMLPlatformUtils::Terminate();
1.输出结果为
对应节点值为:test11
总结:
读取XML有两种模式,一种是基于事件的SAX方式,一种是DOM,本文采用DOM方式,其实与js中的getElementbyId()有些类似。代码主体是完整的,希望不影响理解。如有需要源代码的,可加QQ或微信:304772487或来信:thpychengai@aliyun.com
原文:http://www.cnblogs.com/shappy/p/4592729.html