1.ID3选择最大化Information Gain的属性进行划分 C4.5选择最大化Gain Ratio的属性进行划分
规避问题:ID3偏好将数据分为很多份的属性
解决:将划分后数据集的个数考虑进去
| entropy | 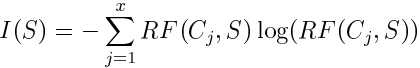 (其中RF-relative frequency) (其中RF-relative frequency)
|
Information Gain->ID3
| 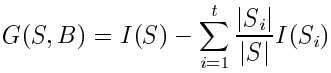
|
potential information of partition
| 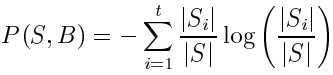
|
Gain Ratio->C4.5
| 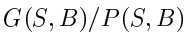
|
当数据被划分成很多份时,每一份占的比例变小,P(S,B)变大,Gain Ratio变小
2.C4.5中加入对missing value的处理
a.在构建树时
属性选择
按属性B进行划分,该属性为空的数据被标记为S0,不参与计算
当空值占多数时,G会偏小,使不偏向于选择空值多的属性
属性B为空的数据,按其他类的比例分入子类中
Si类会得到|S0|*
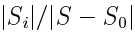
各S0数据
b.进行预测时
叶子节点的各类预测的概率为其比例,比如(0.25,0.5,0.25)
在碰到节点,使用属性B进行划分,而此时要预测的数据Y,B为空,
则需要遍历各个子树的分类结果,并按各个子树构建时划分到的数据的数量多少决定权重
3.剪枝
没看明白...
C4.5较ID3的改进
原文:http://www.cnblogs.com/porco/p/4605668.html