算法思想:存在一个样本数据集合,也称作训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分类的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本集中特征最相似数据的分类标签。最后选择k个最相似数据中出现次数最多的分类,最为新数据的分类。
2.1导入数据

导入使用的数据,在此只有2个类标签:A和B
2.2实施kNN算法
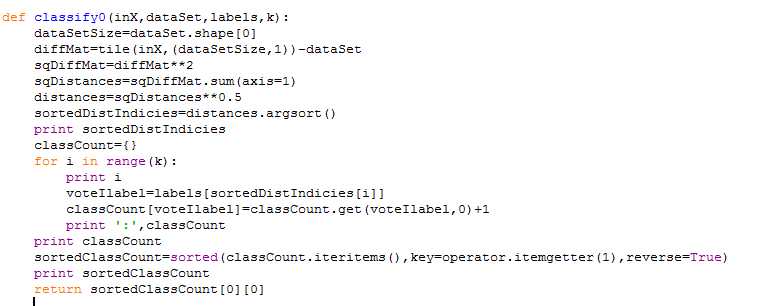
sortedClassCount=sorted(classCount.iteritems(),key=operator.itemgetter(1),reverse=True),用迭代器以值为基准进行反向排序,返回的是元组列表,
return sortedClassCount[0][0]列表第一个元素(一个元组)的第一个值即为待分类数据的类标签。

看一下结果吧,[1,2]的分类是A
2.3看一下书上的例子吧
First--改进约会网站的配对效果

首先要做的当然还是导入数据,returnMat特征矩阵,classLabelVector类标签列表。
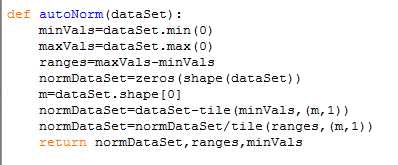
为了使三个特征的权重相同,需要归一化数据,在此采用newValues=(oldValues-min)/(max-min)
然后随机选择10%的数据用于测试,90%的数据用于训练算法,这里就不贴图了。。。
原文:http://www.cnblogs.com/woshikafeidouha/p/3572246.html