网络上大部分关于python爬虫的介绍以及代码讲解,都用的是python2.7或以下版本,用python3.x版本的甚少。
在python3.3.2版本中,没有urllib2这个库,也没有cookiejar这个库。对应的库分别是http.cookiejar以及urllib这俩。
关于url以及python2.7爬虫写法的介绍,可以参考[Python]网络爬虫(一):抓取网页的含义和URL基本构成这系列的文章。我这里主要介绍的是python3.3.2的urllib2的实现。
首先,下面是一个简单的抓取网页信息程序,主要是介绍下urllib的使用。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15 |
# 简单的抓取HOJ主页的数据import
urllib.requesthtml =
response.read()print(html)# 注意,由于网页抓取下来的是bytes格式的数据,所以写入文件时需要以二进制的方式写入fout =
open(‘txt.txt‘,‘wb‘)fout.write(html)fout.close()fout =
open(‘html.html‘,‘wb‘) # 写入到文件html.htmlfout.write(html)fout.close() |
运行结果应该是txt.txt,html.html两个文件。我们可以打开看看txt.txt、html.html看看,发现txt.txt的数据跟浏览器查看的网页源代码一致。如果用浏览器打开html.html,会发现这个跟我们实际上考看到的网页基本一样。
模拟HOJ登陆并抓取已经AC的代码
我们需要进行登陆,需要设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie。
|
1
2
3
4
5 |
# 设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookiecj =
http.cookiejar.LWPCookieJar() cookie_support =
urllib.request.HTTPCookieProcessor(cj) opener =
urllib.request.build_opener(cookie_support, urllib.request.HTTPHandler) urllib.request.install_opener(opener) |
登陆时需要对HOJ服务器发送数据请求,对于发送data表单数据,我们怎么查看需要发送的数据?在HTTP中,这个经常使用熟知的POST请求发送。
我们可以先查看网页源代码,看到

看到三个name,所以发送的求情数据中需要包含这三个,
|
1
2
3
4
5
6 |
# 构造Post数据,从抓大的包里分析得出的或者通过查看网页源代码可以得到 data =
{ ‘user‘
: user, # 你的用户名 ‘password‘
: password, # 你的密码,密码可能是明文传输也可能是密文,如果是密文需要调用相应的加密算法加密 ‘submit‘
: ‘Login‘
# 特有数据,不同网站可能不同} |
另外,一般的HTML表单,data需要编码成标准形式。然后做为data参数传到Request对象。所以我们需要对data进行编码。
|
1 |
data =
urllib.parse.urlencode(data).encode(‘utf-8‘) |
发送请求,得到服务器给我们的响应,完成登录功能。header最好加上,不然由于内部信息默认显示为机器代理,可能被服务器403 Forbidden拒绝访问。
|
1
2
3
4 |
# 发送请求,得到服务器给我们的响应response =
urllib.request.Request(url, data,header)# 通过urllib提供的request方法来向指定Url发送我们构造的数据,并完成登录过程urllib.request.urlopen(response) |
登录函数如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32 |
def login(): # 登陆函数 print(‘请输入你的账号‘) user =
input() print(‘请输入你的密码‘) password =
input() # 设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie cj =
http.cookiejar.LWPCookieJar() cookie_support =
urllib.request.HTTPCookieProcessor(cj) opener =
urllib.request.build_opener(cookie_support, urllib.request.HTTPHandler) urllib.request.install_opener(opener) # 这个最好加上,不然由于内部信息默认显示为机器代理,可能被服务器403 Forbidden拒绝访问 header={‘User-Agent‘:‘Magic Browser‘} # 构造Post数据,从抓大的包里分析得出的或者通过查看网页源代码可以得到 data =
{ ‘user‘
: user, # 你的用户名 ‘password‘
: password, # 你的密码,密码可能是明文传输也可能是密文,如果是密文需要调用相应的加密算法加密 ‘submit‘
: ‘Login‘
# 特有数据,不同网站可能不同 } data =
urllib.parse.urlencode(data).encode(‘utf-8‘) # 发送请求,得到服务器给我们的响应 response =
urllib.request.Request(url, data,header) # 通过urllib提供的request方法来向指定Url发送我们构造的数据,并完成登录过程 urllib.request.urlopen(response) return |
登录进去后,我们需要对已经AC的代码进行抓取。抓取的链接为:
http://acm.hit.edu.cn/hoj/problem/solution/?problem=题目编号
|
1
2
3 |
response =
urllib.request.urlopen(url)html =
response.read() |
我们可以把html输出看看具体内容是什么。
通过查看网页代码,发现提交的代码都是在<span></span>标签中。
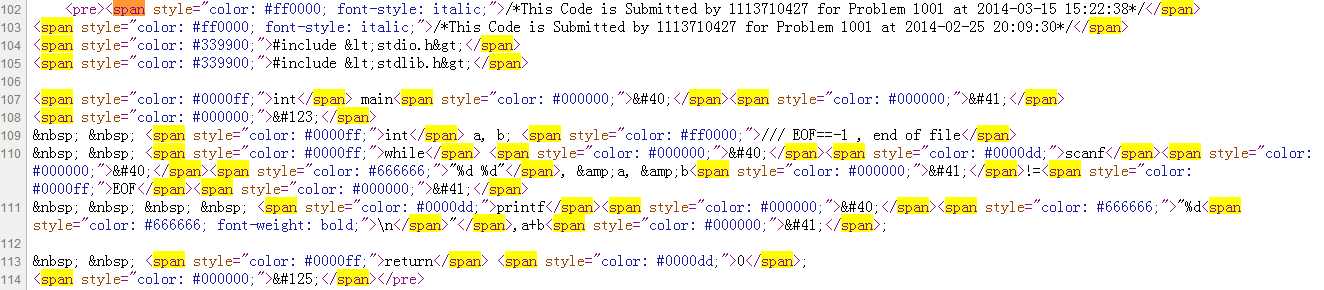
因此我们可以对这部分数据进行处理,处理过程中我们可以用到python的正则表达式进行搜索。并且对于特殊的编码如<需要进行解码。
当然,我们需要注意保存的文件到底是java还是c++。
最后,详细的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121 |
import
urllibimport
http.cookiejar#import timehashTable =
{ # 网页特殊编码转化 ‘<‘:‘<‘, ‘>‘: ‘>‘, ‘{‘:‘{‘, ‘}‘:‘}‘, ‘(‘:‘(‘, ‘)‘:‘)‘, ‘ ‘:‘ ‘, ‘&‘:‘&‘, ‘[‘:‘[‘, ‘]‘:‘]‘, ‘"‘:‘"‘ }def
login(): # 登陆函数 print(‘请输入你的账号‘) user =
input() print(‘请输入你的密码‘) password =
input() # 设置一个cookie处理器,它负责从服务器下载cookie到本地,并且在发送请求时带上本地的cookie cj =
http.cookiejar.LWPCookieJar() cookie_support =
urllib.request.HTTPCookieProcessor(cj) opener =
urllib.request.build_opener(cookie_support, urllib.request.HTTPHandler) urllib.request.install_opener(opener) # 这个最好加上,不然由于内部信息默认显示为机器代理,可能被服务器403 Forbidden拒绝访问 header={‘User-Agent‘:‘Magic Browser‘} # 构造Post数据,从抓大的包里分析得出的或者通过查看网页源代码可以得到 data =
{ ‘user‘
: user, # 你的用户名 ‘password‘
: password, # 你的密码,密码可能是明文传输也可能是密文,如果是密文需要调用相应的加密算法加密 ‘submit‘
: ‘Login‘
# 特有数据,不同网站可能不同 } data =
urllib.parse.urlencode(data).encode(‘utf-8‘) # 发送请求,得到服务器给我们的响应 response =
urllib.request.Request(url, data,header) # 通过urllib提供的request方法来向指定Url发送我们构造的数据,并完成登录过程 urllib.request.urlopen(response) returndef
solve(html,i): txt =
html.decode(‘gbk‘,‘ignore‘) start =
txt.find(‘<span‘) if
start==-1: # 没有span,表示此题没AC return p =
‘.java‘ if
txt.find(‘import‘)==-1: p =
‘.cpp‘ fout =
open(‘txt_‘+str(i)+p,‘w‘) while
True: end =
txt.find(‘<span‘,start+5) if
end==-1: end =
txt.find(‘</span>‘,start) x =
txt.find(‘>‘,start)+1 w =
‘‘ ok =
True while
x<end: if
txt[x]==‘<‘: ok =
False elif
txt[x]==‘>‘: ok =
True if
not ok or
txt[x]==‘>‘: x +=
1 continue if
txt[x]==‘&‘: # 进行特殊的解码 t4 =
txt[x:x+4] t5 =
txt[x:x+5] t6 =
txt[x:x+6] if
t4 in
hashTable: w +=
hashTable[t4] x +=
4 elif
t5 in
hashTable: w +=
hashTable[t5] x +=
5 elif
t6 in
hashTable: w +=
hashTable[t6] x +=
6 else: w +=
txt[x] x +=
1 else: w +=
txt[x] x +=
1 fout.write(w) if
end==start: break start =
end fout.close() returndef
run(): # 抓取所有AC代码 for
i in
range(1001,3169): response =
urllib.request.urlopen(url) html =
response.read() solve(html,i) #time.sleep(0.5) # 时间间隔为0.5s发送一次抓取请求,减轻hoj服务器压力 returnlogin()run() |
我所有的HOJ AC代码,在http://pan.baidu.com/s/1gdsX9DL
提交AC代码:
这个其实跟登陆并抓取AC代码原理基本一样。

|
1
2
3
4
5
6 |
# 构造Post数据,从网页数据分析得出data =
{ ‘Proid‘
: num, ‘Language‘
: language, ‘Source‘
: txt # 可以通过查看网页源代码看出} |
另外,我们需要用到listdir()函数,以此来获得当前目录下所有的文件。
这里我们需要设置time.sleep(3) ,间隔三秒递交一次代码,减轻服务器压力,以免使得HOJ服务器崩了。
总的代码如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89 |
import
urllibimport
http.cookiejarimport
timefrom os import
listdirdef login(): print(‘请输入你的账号‘) user =
input() print(‘请输入你的密码‘) password =
input() cj =
http.cookiejar.LWPCookieJar() cookie_support =
urllib.request.HTTPCookieProcessor(cj) opener =
urllib.request.build_opener(cookie_support, urllib.request.HTTPHandler) urllib.request.install_opener(opener) header =
{‘User-Agent‘
: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1‘, ‘Referer‘
: ‘******‘} # 构造Post数据,他也是从抓大的包里分析得出的。 data =
{‘op‘
: ‘dmlogin‘, ‘f‘
: ‘st‘, ‘user‘
: user, # 用户名 ‘password‘
: password, # 密码,密码可能是明文传输也可能是密文,如果是密文需要调用相应的加密算法加密 ‘submit‘
: ‘Login‘
# 特有数据,不同网站可能不同 } data =
urllib.parse.urlencode(data).encode(‘utf-8‘) request =
urllib.request.Request(url, data,header) # 通过urllib2提供的request方法来向指定Url发送我们构造的数据,并完成登录过程 urllib.request.urlopen(request) returndef
solve(file): # file:为文件名,格式是 txt_problemNumber.cpp或者 txt_problemNumber.java ed =
file.find(‘.‘) language =
file[ed+1:len(file)] if
language!=‘cpp‘
and language!=‘java‘: return if
language==‘cpp‘: language =
‘C++‘ else: language =
‘Java‘ st =
file.find(‘_‘) num =
file[st+1:ed] header =
{‘User-Agent‘
: ‘Mozilla/5.0 (Windows NT 6.1; WOW64; rv:14.0) Gecko/20100101 Firefox/14.0.1‘, ‘Referer‘
: ‘******‘} fin =
open(file,‘rb‘) txt =
fin.read().decode(‘gbk‘,‘ignore‘) fin.close() # 构造Post数据,从网页数据分析得出 data =
{ ‘Proid‘
: num, ‘Language‘
: language, ‘Source‘
: txt # 可以通过查看网页源代码看出 } data =
urllib.parse.urlencode(data).encode(‘utf-8‘) # 使用UTF-8编码方式进行编码 request =
urllib.request.Request(url, data,header) # 添加消息头 # 通过urllib2提供的request方法来向指定Url发送我们构造的数据,并完成登录过程 urllib.request.urlopen(request) time.sleep(3) # 间隔三秒递交一次代码,减轻服务器压力 returndef
run(): allFile =
listdir() # 获得当前目录下所有的文件 for
file in allFile: solve(file) returnlogin()run() |
python 3.3.2 爬虫记录,布布扣,bubuko.com
原文:http://www.cnblogs.com/yejinru/p/3601905.html